Riccardo Cardin
33 min read •

Share on:
Version 19 of Java came at the end of 2022, bringing us a lot of exciting stuff. One of the coolest is the preview of some hot topics concerning Project Loom: virtual threads (JEP 425) and structured concurrency (JEP 428). Whereas still in a preview phase (to tell the truth, structured concurrency is still in the incubator module), the two JEPs promise to bring modern concurrency paradigms that we already found in Kotlin (coroutines) and Scala (Cats Effect and ZIO fibers) also in the mainstream language of the JVM: The Java programming language.
Without further ado, let’s first introduce virtual threads. As we said, both projects are still evolving, so the final version of the features might differ from what we will see here. Future articles to come will focus on structured concurrency and other cool features of Project Loom.
As we said, both the JEPs are still in the preview/incubation step, so we must enable them in our project. At the end of the article, we will give an example of a Maven configuration with all the needed dependencies and configurations. Here, we will just show the most important parts.
First, we need to use a version of Java that is at least 19. Then, we must give the JVM the --enable-preview flag. Although we will not talk about structured concurrency, we set up the environment to access it. So, we need to enable and import the jdk.incubator.concurrent module. Under the folder src/main/java, we need to create a file named module-info.java with the following content:
module virtual.threads.playground {
requires jdk.incubator.concurrent;
}
The name of our module doesn’t matter. We used virtual.threads.playground, but we can use any name we want. The important thing is that we need to use the requires directive to enable the incubator module.
We’ll use Slf4j to log something on the console. So, all the code snippets in this article will use the following logger:
static final Logger logger = LoggerFactory.getLogger(App.class);
However, we won’t use the logger object directly in our example but the following custom function log:
static void log(String message) {
logger.info("{} | " + message, Thread.currentThread());
}
In fact, the above function allows us to print some helpful information concerning virtual threads that will be very handy in understanding what’s going on.
Moreover, we’ll also use Lombok to reduce the boilerplate code when dealing with checked exceptions. So, we’ll use the @SneakyThrows, which lets us treat checked exceptions as unchecked ones (don’t use it in production!). For example, we’ll wrap the Thread.sleep method, which throws a checked InterruptedException, with the @SneakyThrows annotation:
@SneakyThrows
private static void sleep(Duration duration) {
Thread.sleep(duration);
}
Since we’re in an application using Java modules, we need both dependencies and the required modules. The above module declaration then becomes the following:
module virtual.threads.playground {
requires jdk.incubator.concurrent;
requires org.slf4j;
requires static lombok;
}
For people who already follow us, we asked the same question in the article Kotlin 101: Coroutines Quickly Explained. However, it is essential to briefly introduce the problem virtual threads are trying to solve.
The JVM is a multithreaded environment. As we may know, the JVM gives us an abstraction of OS threads through the type java.lang.Thread. Until Project Loom, every thread in the JVM is just a little wrapper around an OS thread. We can call the such implementation of the java.lang.Thread type as platform thread.
The problem with platform threads is that they are expensive from a lot of points of view. First, they are costly to create. Whenever a platform thread is made, the OS must allocate a large amount of memory (megabytes) in the stack to store the thread context, native, and Java call stacks. This is due to the not resizable nature of the stack. Moreover, whenever the scheduler preempts a thread from execution, this enormous amount of memory must be moved around.
As we can imagine, this is a costly operation, in space and time. In fact, the massive size of the stack frame limits the number of threads that can be created. We can reach an OutOfMemoryError quite easily in Java, continually instantiating new platform threads till the OS runs out of memory:
private static void stackOverFlowErrorExample() {
for (int i = 0; i < 100_000; i++) {
new Thread(() -> {
try {
Thread.sleep(Duration.ofSeconds(1L));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}).start();
}
}
The results depend on the OS and the hardware, but we can easily reach an OutOfMemoryError in a few seconds:
[0.949s][warning][os,thread] Failed to start thread "Unknown thread" - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached.
[0.949s][warning][os,thread] Failed to start the native thread for java.lang.Thread "Thread-4073"
Exception in thread "main" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reached
The above example shows how we wrote concurrent programs that were constrained until now.
Java has been a language that has tried to strive for simplicity since its inception. In concurrent programming, we should write programs as if they were sequential. In fact, the more straightforward way to write concurrent programs in Java is to create a new thread for every concurrent task. This model is called one task per thread.
In such an approach, every thread can use its own local variable to store information. The need to share mutable states among threads, the well-known “hard part” of concurrent programming, drastically decreases. However, using such an approach, we can easily reach the limit of the number of threads we can create.
As we said in the article concerning Kotlin Coroutines, many approaches have risen in recent years to overcome the above problem. The first attempt was to introduce a model of programming based on callback. For each asynchronous statement, we also give a callback to call once the statement finishes:
static void callbackHell() {
a(aInput, resultFromA ->
b(resultFromA, resultFromB ->
c(resultFromB, resultFromC ->
d(resultFromC, resultFromD ->
System.out.printf("A, B, C, D: $resultFromA, $resultFromB, $resultFromC, $resultFromD")))));
}
The above code is a simple example of callback hell. The code is not easy to read and understand. Moreover, it is not easy to write.
To overcome the problems of callbacks, reactive programming, and async/await strategies were introduced.
The reactive programming initiatives try to overcome the lack of thread resources by building a custom DSL to declaratively describe the data flow and let the framework handle concurrency. However, DSL is tough to understand and use, losing the simplicity Java tries to give us.
Also, the async/await approach, such as Kotlin coroutines, has its own problems. Even though it aims to model the one task per thread approach, it can’t rely on any native JVM construct. For example, Kotlin coroutines based the whole story on suspending functions, i.e., functions that can suspend a coroutine. However, the suspension is wholly based upon non-blocking IO, which we can achieve using libraries based on Netty, but not every task can be expressed in terms of non-blocking IO. Ultimately, we must divide our program into two parts: one based on non-blocking IO (suspending functions) and one that does not. This is a challenging task; it takes work to do it correctly. Moreover, we lose again the simplicity we want in our programs.
The above are reasons why the JVM community is looking for a better way to write concurrent programs. Project Loom is one of the attempts to solve the problem. So, let’s introduce the first brick of the project: virtual threads.
As we said, virtual threads are a new type of thread that tries to overcome the resource limitation problem of platform threads. They are an alternate implementation of the java.lang.Thread type, which stores the stack frames in the heap (garbage-collected memory) instead of the stack.
Therefore, the initial memory footprint of a virtual thread tends to be very small, a few hundred bytes instead of megabytes. In fact, the stack chunk can resize at every moment. So, we don’t need to allocate a gazillion of memory to fit every possible use case.
Creating a new virtual thread is very easy. We can use the new factory method ofVirtual on the java.lang.Thread type. Let’s first define a utility function to create a virtual thread with a given name:
private static Thread virtualThread(String name, Runnable runnable) {
return Thread.ofVirtual()
.name(name)
.start(runnable);
}
We’ll use the same example in the Kotlin Coroutine article to show how virtual threads work. Let’s describe our morning routine. Every morning, we take a bath:
static Thread bathTime() {
return virtualThread(
"Bath time",
() -> {
log("I'm going to take a bath");
sleep(Duration.ofMillis(500L));
log("I'm done with the bath");
});
}
Another task that we do is to boil some water to make tea:
static Thread boilingWater() {
return virtualThread(
"Boil some water",
() -> {
log("I'm going to boil some water");
sleep(Duration.ofSeconds(1L));
log("I'm done with the water");
});
}
Fortunately, we can race the two tasks to speed up the process and go to work earlier:
@SneakyThrows
static void concurrentMorningRoutine() {
var bathTime = bathTime();
var boilingWater = boilingWater();
bathTime.join();
boilingWater.join();
}
We joined both virtual threads, so we can be sure that the main thread will not terminate before the two virtual threads. Let’s run the program:
08:34:46.217 [boilWater] INFO in.rcard.virtual.threads.App - VirtualThread[#21,boilWater]/runnable@ForkJoinPool-1-worker-1 | I'm going to take a bath
08:34:46.218 [boilWater] INFO in.rcard.virtual.threads.App - VirtualThread[#23,boilWater]/runnable@ForkJoinPool-1-worker-2 | I'm going to boil some water
08:34:46.732 [bath-time] INFO in.rcard.virtual.threads.App - VirtualThread[#21,boilWater]/runnable@ForkJoinPool-1-worker-2 | I'm done with the bath
08:34:47.231 [boilWater] INFO in.rcard.virtual.threads.App - VirtualThread[#23,boilWater]/runnable@ForkJoinPool-1-worker-2 | I'm done with the water
The output is what we expected. The two virtual threads run concurrently, and the main thread waits for them to terminate. We’ll explain all the information printed by the log in a while. For now, let’s focus solely on thread name and execution interleaving.
Besides the factory method, we can use a new implementation of the java.util.concurrent.ExecutorService tailored on virtual threads, called java.util.concurrent.ThreadPerTaskExecutor. Its name is quite evocative. It creates a new virtual thread for every task submitted to the executor:
@SneakyThrows
static void concurrentMorningRoutineUsingExecutors() {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var bathTime =
executor.submit(
() -> {
log("I'm going to take a bath");
sleep(Duration.ofMillis(500L));
log("I'm done with the bath");
});
var boilingWater =
executor.submit(
() -> {
log("I'm going to boil some water");
sleep(Duration.ofSeconds(1L));
log("I'm done with the water");
});
bathTime.get();
boilingWater.get();
}
}
The way we start threads is a little different since we’re using the ExecutorService. Every call to the submit method requires a Runnable or a Callable<T> instance. The submit returns a Future<T> instance that we can use to join the underlying virtual thread.
The output is more or less the same as before:
08:42:09.164 [] INFO in.rcard.virtual.threads.App - VirtualThread[#21]/runnable@ForkJoinPool-1-worker-1 | I'm going to take a bath
08:42:09.164 [] INFO in.rcard.virtual.threads.App - VirtualThread[#23]/runnable@ForkJoinPool-1-worker-2 | I'm going to boil some water
08:42:09.676 [] INFO in.rcard.virtual.threads.App - VirtualThread[#21]/runnable@ForkJoinPool-1-worker-2 | I'm done with the bath
08:42:10.175 [] INFO in.rcard.virtual.threads.App - VirtualThread[#23]/runnable@ForkJoinPool-1-worker-2 | I'm done with the water
As we can see, threads created this way do not have a name, and debugging errors without a name can be difficult. We can overcome this problem just by using the newThreadPerTaskExecutor factory method that takes a ThreadFactory as a parameter:
@SneakyThrows
static void concurrentMorningRoutineUsingExecutorsWithName() {
final ThreadFactory factory = Thread.ofVirtual().name("routine-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
var bathTime =
executor.submit(
() -> {
log("I'm going to take a bath");
sleep(Duration.ofMillis(500L));
log("I'm done with the bath");
});
var boilingWater =
executor.submit(
() -> {
log("I'm going to boil some water");
sleep(Duration.ofSeconds(1L));
log("I'm done with the water");
});
bathTime.get();
boilingWater.get();
}
}
A ThreadFactory is a factory that creates threads with the same configuration. In our case, we give the prefix routine- to the name of the threads, and we start the counter from 0. The output is the same as before, but now we can see the name of the threads:
08:44:35.390 [routine-1] INFO in.rcard.virtual.threads.App - VirtualThread[#23,routine-1]/runnable@ForkJoinPool-1-worker-2 | I'm going to boil some water
08:44:35.390 [routine-0] INFO in.rcard.virtual.threads.App - VirtualThread[#21,routine-0]/runnable@ForkJoinPool-1-worker-1 | I'm going to take a bath
08:44:35.900 [routine-0] INFO in.rcard.virtual.threads.App - VirtualThread[#21,routine-0]/runnable@ForkJoinPool-1-worker-1 | I'm done with the bath
08:44:36.399 [routine-1] INFO in.rcard.virtual.threads.App - VirtualThread[#23,routine-1]/runnable@ForkJoinPool-1-worker-1 | I'm done with the water
Now that we know how to create virtual threads let’s see how they work.
How do virtual threads work? The figure below shows the relationship between virtual threads and platform threads:
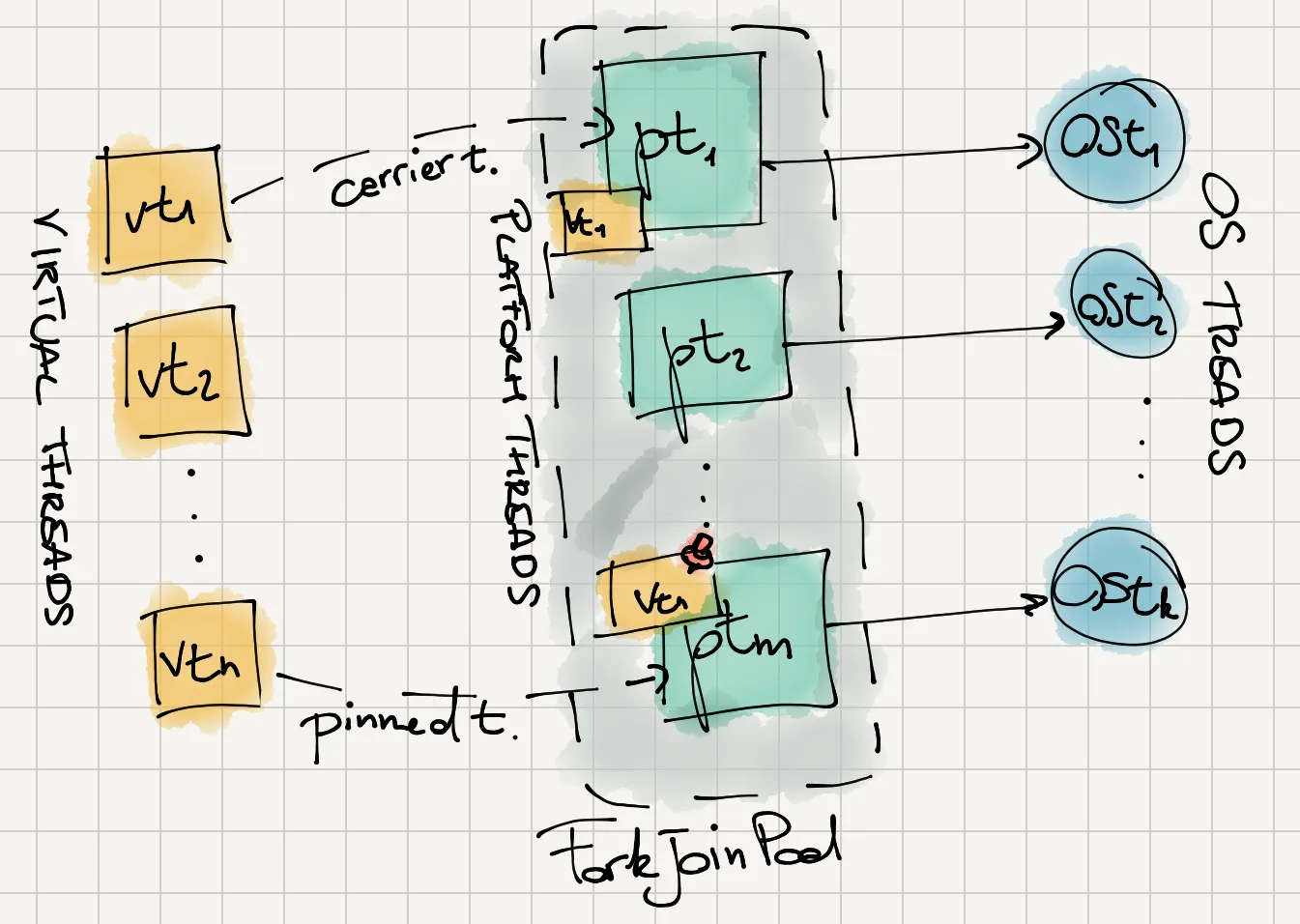
The JVM maintains a pool of platform threads, created and maintained by a dedicated ForkJoinPool. Initially, the number of platform threads equals the number of CPU cores, and it cannot increase more than 256.
For each created virtual thread, the JVM schedules its execution on a platform thread, temporarily copying the stack chunk for the virtual thread from the heap to the stack of the platform thread. We said that the platform thread becomes the carrier thread of the virtual thread.
The logs we’ve seen so far showed us precisely the above situation. Let’s analyze one of them:
08:44:35.390 [routine-1] INFO in.rcard.virtual.threads.App - VirtualThread[#23,routine-1]/runnable@ForkJoinPool-1-worker-2 | I'm going to boil some water
The exciting part is on the left side of the | character. The first part identifies the virtual thread in execution: VirtualThread[#23,routine-1] reports the thread identifier, the #23 part, and the thread name. Then, we have the indication on which carrier thread the virtual thread executes: ForkJoinPool-1-worker-2 represents the platform thread called worker-2 of the default ForkJoinPool, called ForkJoinPool-1.
The first time the virtual thread blocks on a blocking operation, the carrier thread is released, and the stack chunk of the virtual thread is copied back to the heap. This way, the carrier thread can execute any other eligible virtual threads. Once the blocked virtual thread finishes the blocking operation, the scheduler schedules it again for execution. The execution can continue on the same carrier thread or a different one.
We can easily see that the number of available carrier threads is equal to the number of CPU cores by default running a program that creates and starts a number of virtual threads greater than the number of cores. On a Mac, you can retrieve the number of cores by running the following command:
sysctl hw.physicalcpu hw.logicalcpu
We are interested in the second value, which counts the number of logical cores. On my machine, I have 2 physical cores and 4 logical cores. Let’s define a function to retrieve the number of logical cores in Java:
static int numberOfCores() {
return Runtime.getRuntime().availableProcessors();
}
Then, we can create a program that makes the desired number of virtual threads, i.e., the number of logical cores plus one:
static void viewCarrierThreadPoolSize() {
final ThreadFactory factory = Thread.ofVirtual().name("routine-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
IntStream.range(0, numberOfCores() + 1)
.forEach(i -> executor.submit(() -> {
log("Hello, I'm a virtual thread number " + i);
sleep(Duration.ofSeconds(1L));
}));
}
}
We expect the 5 virtual threads to be executed on 4 carrier threads, and one of the carrier threads should be reused at least once. Running the program, we can see that our hypothesis is correct:
08:44:54.849 [routine-0] INFO in.rcard.virtual.threads.App - VirtualThread[#21,routine-0]/runnable@ForkJoinPool-1-worker-1 | Hello, I'm a virtual thread number 0
08:44:54.849 [routine-1] INFO in.rcard.virtual.threads.App - VirtualThread[#23,routine-1]/runnable@ForkJoinPool-1-worker-2 | Hello, I'm a virtual thread number 1
08:44:54.849 [routine-2] INFO in.rcard.virtual.threads.App - VirtualThread[#24,routine-2]/runnable@ForkJoinPool-1-worker-3 | Hello, I'm a virtual thread number 2
08:44:54.855 [routine-4] INFO in.rcard.virtual.threads.App - VirtualThread[#26,routine-4]/runnable@ForkJoinPool-1-worker-4 | Hello, I'm a virtual thread number 4
08:44:54.849 [routine-3] INFO in.rcard.virtual.threads.App - VirtualThread[#25,routine-3]/runnable@ForkJoinPool-1-worker-4 | Hello, I'm a virtual thread number 3
There are four carrier threads, ForkJoinPool-1-worker-1, ForkJoinPool-1-worker-2, ForkJoinPool-1-worker-3, and ForkJoinPool-1-worker-4, and the ForkJoinPool-1-worker-4 is reused twice. Awesome!
The above log should ring a bell in the astute reader. How the JVM schedules virtual threads on their carrier threads? Is there any preemption? Does the JVM use cooperative scheduling instead? Let’s answer these questions in the next session.
Virtual threads are scheduled using a FIFO queue consumed by a dedicated ForkJoinPool. The default scheduler is defined in the java.lang.VirtualThread class:
// SDK code
final class VirtualThread extends BaseVirtualThread {
private static final ForkJoinPool DEFAULT_SCHEDULER = createDefaultScheduler();
// Omissis
private static ForkJoinPool createDefaultScheduler() {
// Omissis
int parallelism, maxPoolSize, minRunnable;
String parallelismValue = System.getProperty("jdk.virtualThreadScheduler.parallelism");
String maxPoolSizeValue = System.getProperty("jdk.virtualThreadScheduler.maxPoolSize");
String minRunnableValue = System.getProperty("jdk.virtualThreadScheduler.minRunnable");
// Omissis
return new ForkJoinPool(parallelism, factory, handler, asyncMode,
0, maxPoolSize, minRunnable, pool -> true, 30, SECONDS);
}
}
Configuring the pool dedicated to carrier threads is possible using the above system properties. The default pool size (parallelism) equals the number of CPU cores, and the maximum pool size is at most 256. The minimum number of core threads not blocked allowed is half the pool size.
In Java, virtual threads implement cooperative scheduling. As we saw in Kotlin 101: Coroutines Quickly Explained, it’s a virtual thread that decides when to yield the execution to another virtual thread. In detail, the control is passed to the scheduler, and the virtual thread is unmounted from the carrier thread when it reaches a blocking operation.
We can empirically verify this behavior using the sleep() method and the above system properties. First, let’s define a function creating a virtual thread that contains an infinite loop. Let’s say we want to model an employee that is working hard on a task:
static Thread workingHard() {
return virtualThread(
"Working hard",
() -> {
log("I'm working hard");
while (alwaysTrue()) {
// Do nothing
}
sleep(Duration.ofMillis(100L));
log("I'm done with working hard");
});
}
As we can see, the IO operation, the sleep() method, is after the infinite loop. We also defined an alwaysTrue() function, which returns true and allows us to write an infinite loop without using the while (true) construct that is not permitted by the compiler.
Then, we define a function to let our employees take a break:
static Thread takeABreak() {
return virtualThread(
"Take a break",
() -> {
log("I'm going to take a break");
sleep(Duration.ofSeconds(1L));
log("I'm done with the break");
});
}
Now, we can compose the two functions and let the two thread race:
@SneakyThrows
static void workingHardRoutine() {
var workingHard = workingHard();
var takeABreak = takeABreak();
workingHard.join();
takeABreak.join();
}
Before running the workingHardRoutine() function, we set the three system properties:
-Djdk.virtualThreadScheduler.parallelism=1
-Djdk.virtualThreadScheduler.maxPoolSize=1
-Djdk.virtualThreadScheduler.minRunnable=1
The above settings force the scheduler to use a pool configured with only one carrier thread. Since the workingHard virtual thread never reaches a blocking operation, it will never yield the execution to the takeABreak" virtual thread. In fact, the output is the following:
21:28:35.702 [Working hard] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Working hard]/runnable@ForkJoinPool-1-worker-1 | I'm working hard
--- Running forever ---
The workingHard virtual thread is never unmounted from the carrier thread, and the takeABreak virtual thread is never scheduled.
Let’s now change things to let the cooperative scheduling work. We define a new function simulating an employee that is working hard but stops working every 100 milliseconds:
static Thread workingConsciousness() {
return virtualThread(
"Working consciousness,
() -> {
log("I'm working hard");
while (alwaysTrue()) {
sleep(Duration.ofMillis(100L));
}
log("I'm done with working hard");
});
}
Now, the execution can reach the blocking operation, and the workingHard virtual thread can be unmounted from the carrier thread. To verify this, we can race the above thread with the takeABreak thread:
@SneakyThrows
static void workingConsciousnessRoutine() {
var workingConsciousness = workingConsciousness();
var takeABreak = takeABreak();
workingConsciousness.join();
takeABreak.join();
}
This time, we expect the takeABreak virtual thread to be scheduled and executed on the only carrier thread when the workingConsciousness reaches the blocking operation. The output confirms our expectations:
21:30:51.677 [Working consciousness] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Working consciousness]/runnable@ForkJoinPool-1-worker-1 | I'm working hard
21:30:51.682 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm going to take a break
21:30:52.688 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm done with the break
--- Running forever ---
As expected, the two virtual threads share the same carrier thread.
Let’s go back to the workingHardRoutine() function. If we change the carrier pool size to 2, we can see that both the workingHard and the takeABreak virtual threads are scheduled on the two carrier threads so they can run concurrently. The new setup is the following:
-Djdk.virtualThreadScheduler.parallelism=2
-Djdk.virtualThreadScheduler.maxPoolSize=2
-Djdk.virtualThreadScheduler.minRunnable=2
As we might expect, the output is the following. While the ForkJoinPool-1-worker-1 is stuck in the infinite loop, the ForkJoinPool-1-worker-2 is executing the takeABreak virtual thread:
21:33:43.641 [Working hard] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Working hard]/runnable@ForkJoinPool-1-worker-1 | I'm working hard
21:33:43.641 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#24,Take a break]/runnable@ForkJoinPool-1-worker-2 | I'm going to take a break
21:33:44.655 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#24,Take a break]/runnable@ForkJoinPool-1-worker-2 | I'm done with the break
--- Running forever ---
It’s worth mentioning that cooperative scheduling is helpful when working in a highly collaborative environment. Since a virtual thread releases its carrier thread only when reaching a blocking operation, cooperative scheduling and virtual threads will not improve the performance of CPU-intensive applications. The JVM already gives us a tool for those tasks: Java parallel streams.
We said that the JVM mounts a virtual thread to a platform thread, its carrier thread, and executes it until it reaches a blocking operation. Then, the virtual thread is unmounted from the carrier thread, and the scheduler decides which virtual thread to schedule on the carrier thread.
However, there are some cases where a blocking operation doesn’t unmount the virtual thread from the carrier thread, blocking the underlying carrier thread. In such cases, we say the virtual is pinned to the carrier thread. It’s not an error but a behavior that limits the application’s scalability. Note that if a carrier thread is pinned, the JVM can always add a new platform thread to the carrier pool if the configurations of the carrier pool allow it.
Fortunately, there are only two cases in which a virtual thread is pinned to the carrier thread:
synchronized block or method;Let’s see an example of pinned virtual thread. We want to simulate an employee that needs to go to the bathroom. The bathroom has only one WC, so the access to the toilet must be synchronized:
static class Bathroom {
synchronized void useTheToilet() {
log("I'm going to use the toilet");
sleep(Duration.ofSeconds(1L));
log("I'm done with the toilet");
}
}
Now, we define a function simulating an employee that uses the bathroom:
static Bathroom bathroom = new Bathroom();
static Thread goToTheToilet() {
return virtualThread(
"Go to the toilet",
() -> bathroom.useTheToilet());
}
In the office, there are Riccardo and Daniel. Riccardo has to go to the bathroom while Daniel wants a break. Since they’re working on different issues, they could complete their task concurrently. Let’s define a function that tries to execute Riccardo and Daniel concurrently:
@SneakyThrows
static void twoEmployeesInTheOffice() {
var riccardo = goToTheToilet();
var daniel = takeABreak();
riccardo.join();
daniel.join();
}
To see the effect of synchronization and the pinning of the associated riccardo virtual thread, we limit the carrier pool to one thread, as we did previously. The execution of the twoEmployeesInTheOffice produces the following output:
16:29:05.548 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm going to use the toilet
16:29:06.558 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm done with the toilet
16:29:06.559 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm going to take a break
16:29:07.563 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm done with the break
As we can see, the tasks are entirely linearized by the JVM. As we said, the blocking sleep operation is inside the synchronized useTheToilet method, so the virtual thread is not unmounted. So, the riccardo virtual thread is pinned to the carrier thread, and the daniel virtual thread finds no available carrier thread to execute. In fact, it is scheduled when the riccardo virtual thread is done with the bathroom.
It’s possible to trace these situations during the execution of a program by adding a property to the run configuration:
-Djdk.tracePinnedThreads=full/short
The full value prints the full stack trace of the pinned virtual thread, while the short value prints only less information. The execution of the twoEmployeesInTheOffice with the above configuration set to the short value produces the following interesting output:
16:29:05.548 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm going to use the toilet
Thread[#22,ForkJoinPool-1-worker-1,5,CarrierThreads]
virtual.threads.playground/in.rcard.virtual.threads.App$Bathroom.useTheToilet(App.java:188) <== monitors:1
16:29:06.558 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm done with the toilet
16:29:06.559 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm going to take a break
16:29:07.563 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm done with the break
As we guessed, the riccardo virtual thread was pinned to its carrier thread. We can also see the name of the carrier thread here. Amazing.
We can change the configuration of the carrier pool to allow the JVM to add a new carrier thread to the pool when needed:
-Djdk.virtualThreadScheduler.parallelism=1
-Djdk.virtualThreadScheduler.maxPoolSize=2
-Djdk.virtualThreadScheduler.minRunnable=1
We also removed the property jdk.tracePinnedThreads to avoid printing the pinned stacktrace. Execution with the new configuration produces the following output:
16:32:05.235 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm going to use the toilet
16:32:05.235 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-2 | I'm going to take a break
16:32:06.243 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm done with the toilet
16:32:06.243 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-2 | I'm done with the break
The JVM added a new carrier thread to the pool when it found no carrier thread. So the daniel virtual thread is scheduled on the new carrier thread, executing concurrently and interleaving the two logs.
Even though soon also synchronized blocks will probably unmount a virtual thread from its carrier thread, it is better to migrate those blocks to the Lock API, using java.util.concurrent.locks.ReentrantLock. Such locks don’t pin the virtual thread, making the cooperative scheduling work again.
Let’s create a version of our Bathroom class using the Lock API:
static class Bathroom {
private final Lock lock = new ReentrantLock();
@SneakyThrows
void useTheToiletWithLock() {
if (lock.tryLock(10, TimeUnit.SECONDS)) {
try {
log("I'm going to use the toilet");
sleep(Duration.ofSeconds(1L));
log("I'm done with the toilet");
} finally {
lock.unlock();
}
}
}
}
Now, let’s change the previous functions to use this new version of the Bathroom class:
static Thread goToTheToiletWithLock() {
return virtualThread("Go to the toilet", () -> bathroom.useTheToiletWithLock());
}
@SneakyThrows
static void twoEmployeesInTheOfficeWithLock() {
var riccardo = goToTheToiletWithLock();
var daniel = takeABreak();
riccardo.join();
daniel.join();
}
The execution of the twoEmployeesInTheOfficeWithLock produces the expected output, which shows the two threads running concurrently:
16:35:58.921 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-2 | I'm going to take a break
16:35:58.921 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-1 | I'm going to use the toilet
16:35:59.932 [Take a break] INFO in.rcard.virtual.threads.App - VirtualThread[#23,Take a break]/runnable@ForkJoinPool-1-worker-1 | I'm done with the break
16:35:59.933 [Go to the toilet] INFO in.rcard.virtual.threads.App - VirtualThread[#21,Go to the toilet]/runnable@ForkJoinPool-1-worker-2 | I'm done with the toilet
We can run the above method also with the jdk.tracePinnedThreads property set to see that no thread is pinned to its carrier thread during the execution.
ThreadLocal and Thread PoolsWhen using threads before Java 19 and Project Loom, creating a thread using the constructor was relatively uncommon. Instead, we preferred to use a thread pool or an executor service configured with a thread pool. In fact, those threads were what we now call platform threads, and the reason was that creating such threads was quite expensive operation.
As we said at the beginning of this article, with virtual threads, it’s not the case anymore. Creating a virtual thread is very cheap, both in space and time. Also, they were designed with the idea of using a different virtual thread for each request. So, it’s worthless to use a thread pool or an executor service to create virtual threads.
As for ThreadLocal, the possible high number of virtual threads created by an application is why using ThreadLocal may not be a good idea.
What is a ThreadLocal? A ThreadLocal is a construct that allows us to store data accessible only by a specific thread. Let’s see an example. First of all, we want to create a ThreadLocal that holds a String:
static ThreadLocal<String> context = new ThreadLocal<>();
Then, we create two different platform threads that use both the ThreadLocal:
@SneakyThrows
static void platformThreadLocal() {
var thread1 = Thread.ofPlatform().name("thread-1").start(() -> {
context.set("thread-1");
sleep(Duration.ofSeconds(1L));
log("Hey, my name is " + context.get());
});
var thread2 = Thread.ofPlatform().name("thread-2").start(() -> {
context.set("thread-2");
sleep(Duration.ofSeconds(1L));
log("Hey, my name is " + context.get());
});
thread1.join();
thread2.join();
}
If we run the above function, the output is:
14:57:05.334 [thread-2] INFO in.rcard.virtual.threads.App - Thread[#22,thread-2,5,main] | Hey, my name is thread-2
14:57:05.334 [thread-1] INFO in.rcard.virtual.threads.App - Thread[#21,thread-1,5,main] | Hey, my name is thread-1
As we can see, each thread stores a different value in the ThreadLocal, which is not accessible to other threads. The thread called thread-1 retrieves the value thread-1 from the ThreadLocal; The thread thread-2 retrieves the value thread-2 instead. There is no race condition at all.
The same properties of ThreadLocal still stand when we speak about virtual threads. In fact, we can replicate the same example above using virtual threads, and the result will be the same:
@SneakyThrows
static void virtualThreadLocal() {
var virtualThread1 = Thread.ofVirtual().name("thread-1").start(() -> {
context.set("thread-1");
sleep(Duration.ofSeconds(1L));
log("Hey, my name is " + context.get());
});
var virtualThread2 = Thread.ofVirtual().name("thread-2").start(() -> {
context.set("thread-2");
sleep(Duration.ofSeconds(1L));
log("Hey, my name is " + context.get());
});
virtualThread1.join();
virtualThread2.join();
}
As we might expect, the output is very similar to the previous one:
15:08:37.142 [thread-1] INFO in.rcard.virtual.threads.App - VirtualThread[#21,thread-1]/runnable@ForkJoinPool-1-worker-1 | Hey, my name is thread-1
15:08:37.142 [thread-2] INFO in.rcard.virtual.threads.App - VirtualThread[#23,thread-2]/runnable@ForkJoinPool-1-worker-2 | Hey, my name is thread-2
Nice. So, is it a good idea to use ThreadLocal with virtual threads? Well, you now need to be careful. The reason is that we can have a huge number of virtual threads, and each virtual thread will have its own ThreadLocal. This means that the memory footprint of the application may quickly become very high. Moreover, the ThreadLocal will be useless in a one-thread-per-request scenario since data won’t be shared between different requests.
However, some scenarios could be help use something similar to ThreadLocal. For this reason, Java 20 will introduce scoped values, which enable the sharing of immutable data within and across threads. However, this is a topic for another article.
In this section, we’ll introduce the implementation of continuation in Java virtual threads. We’re not going into too much detail, but we’ll try to give a general idea of how the virtual threads are implemented.
A virtual thread cannot run itself, but it stores the information of what must be run. In other words, it’s a pointer to the advance of an execution that can be yielded and resumed later.
The above is the definition of continuations. We’ve already seen how Kotlin coroutines implement continuations (Kotlin 101: Coroutines Quickly Explained - Suspending Functions). In that case, the Kotlin compiler generates continuation from the coroutine code. Kotlin’s coroutines have no direct support in the JVM, so they are supported using code generation by the compiler.
However, for virtual threads, we have the JVM support directly. So, continuations execution is implemented using a lot of native calls to the JVM, and it’s less understandable when looking at the JDK code. However, we can still look at some concepts at the roots of virtual threads.
As a continuation, a virtual thread is a state machine with many states. The relations among these states are summarized in the following diagram:
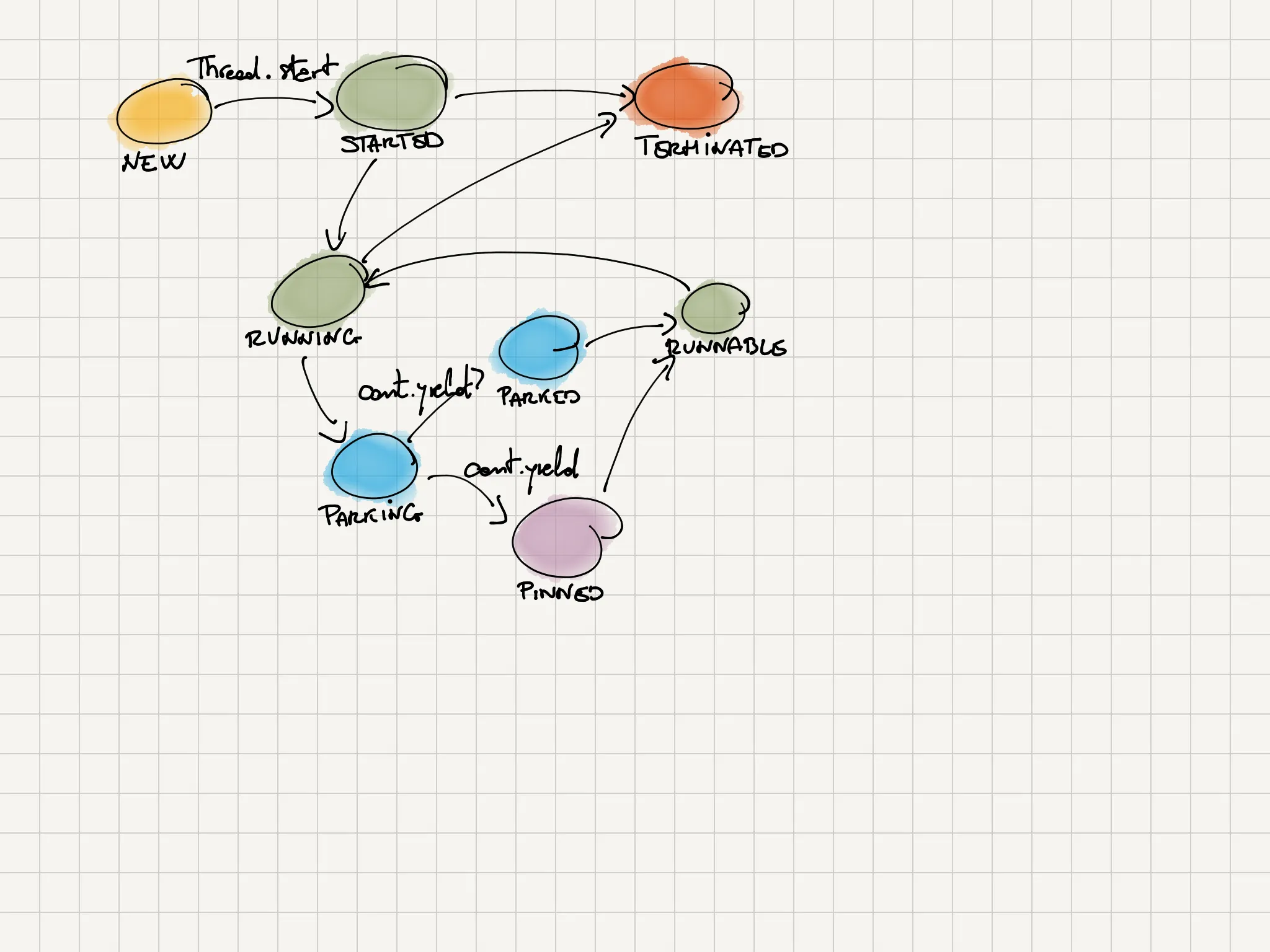
A virtual thread is mounted on its carrier thread when it is in the states colored green in the above diagram. In states colored in light blue, the virtual thread is unmounted from its carrier thread. The pinned state is colored violet.
We get a virtual thread in the NEW status when we call the unstarted method on the object returned by the Thread.ofVirtual() method. The core information is mainly in the java.lang.VirtualThread class. At the core, the JVM calls the VirtualThreadconstructor:
// JDK core code
VirtualThread(Executor scheduler, String name, int characteristics, Runnable task) {
super(name, characteristics, /*bound*/ false);
Objects.requireNonNull(task);
// choose scheduler if not specified
if (scheduler == null) {
Thread parent = Thread.currentThread();
if (parent instanceof VirtualThread vparent) {
scheduler = vparent.scheduler;
} else {
scheduler = DEFAULT_SCHEDULER;
}
}
this.scheduler = scheduler;
this.cont = new VThreadContinuation(this, task);
this.runContinuation = this::runContinuation;
}
As we can see, a scheduler is chosen if not specified. The default scheduler is the one we described in the previous section. After that, a continuation is created, which is a VThreadContinuation object. This object is the one that stores the information of what has to be run as a Runnable object:
// JDK core code
private static class VThreadContinuation extends Continuation {
VThreadContinuation(VirtualThread vthread, Runnable task) {
super(VTHREAD_SCOPE, () -> vthread.run(task));
}
@Override
protected void onPinned(Continuation.Pinned reason) {
if (TRACE_PINNING_MODE > 0) {
boolean printAll = (TRACE_PINNING_MODE == 1);
PinnedThreadPrinter.printStackTrace(System.out, printAll);
}
}
}
The above code also shows how the jdk.tracePinnedThreads flag works. The VTHREAD_SCOPE is a ContinuationScope object, a class used to group continuations. In other words, it’s a way to group continuations related to each other. In our case, we have only one ContinuationScope object, the VTHREAD_SCOPE object. This object is used to group all the virtual threads.
Last, the method sets the runContinuation field, a Runnable object used to run the continuation. This method is called when the virtual thread is started.
Once we call the start method, the virtual thread is moved to the STARTED status:
// JDK core code
@Override
void start(ThreadContainer container) {
if (!compareAndSetState(NEW, STARTED)) {
throw new IllegalThreadStateException("Already start
}
// Omissis
try {
// Omissis
// submit task to run thread
submitRunContinuation();
started = true;
} finally {
// Omissis
}
}
The submitRunContinuation() is the method scheduling the runContinuation runnable to the virtual thread scheduler:
// JDK core code
private void submitRunContinuation(boolean lazySubmit) {
try {
if (lazySubmit && scheduler instanceof ForkJoinPool pool) {
pool.lazySubmit(ForkJoinTask.adapt(runContinuation));
} else {
scheduler.execute(runContinuation);
}
} catch (RejectedExecutionException ree) {
// Omissis
}
}
The execution of the runContinuation runnable moves the virtual thread to the RUNNING status, both if it’s in the STARTED status or in the RUNNABLE status:
// JDK core code
private void runContinuation() {
// Omissis
if (initialState == STARTED && compareAndSetState(STARTED, RUNNING)) {
// first run
firstRun = true;
} else if (initialState == RUNNABLE && compareAndSetState(RUNNABLE, RUNNING)) {
// consume parking permit
setParkPermit(false);
firstRun = false;
} else {
// not runnable
return;
}
// Omissis
try {
cont.run();
} finally {
// Omissis
}
}
From this point on, the state of the virtual threads depends on the execution of the continuation, made through the method Continuation.run(). The method performs a lot of native calls, and it’s not easy to follow the execution flow. However, the first thing it makes is to set as mounted the associated virtual thread:
// JDK core code
public final void run() {
while (true) {
mount();
// A lot of omissis
}
}
Every time the virtual thread reaches a blocking point, the state of the thread is changed to PARKING. The reaching of a blocking point is signaled through the call of the VirtualThread.park() method:
// JDK core code
void park() {
assert Thread.currentThread() == this;
// complete immediately if parking permit available or interrupted
if (getAndSetParkPermit(false) || interrupted)
return;
// park the thread
setState(PARKING);
try {
if (!yieldContinuation()) {
// park on the carrier thread when pinned
parkOnCarrierThread(false, 0);
}
} finally {
assert (Thread.currentThread() == this) && (state() == RUNNING);
}
}
Once in the PARKING state, the yieldContinuation() method is called. This method is the one that performs the actual parking of the virtual thread and tries to unmount the virtual thread from its carrier thread:
// JDK core code
private boolean yieldContinuation() {
boolean notifyJvmti = notifyJvmtiEvents;
// unmount
if (notifyJvmti) notifyJvmtiUnmountBegin(false);
unmount();
try {
return Continuation.yield(VTHREAD_SCOPE);
} finally {
// re-mount
mount();
if (notifyJvmti) notifyJvmtiMountEnd(false);
}
}
The Continuation.yield(VTHREAD_SCOPE) call is implemented with many JVM native calls. If the method returns true, then the parkOnCarrierThreadis called. This method sets the virtual threads as pinned on the carrier thread:
private void parkOnCarrierThread(boolean timed, long nanos) {
assert state() == PARKING;
var pinnedEvent = new VirtualThreadPinnedEvent();
pinnedEvent.begin();
setState(PINNED);
try {
if (!parkPermit) {
if (!timed) {
U.park(false, 0);
} else if (nanos > 0) {
U.park(false, nanos);
}
}
} finally {
setState(RUNNING);
}
// consume parking permit
setParkPermit(false);
pinnedEvent.commit();
}
From there, the method VirtualThread.afterYield() is called. This method sets the PARKED state to the virtual thread, and the continuation is scheduled again for execution through the method lazySubmitRunContinuation() and setting the state to RUNNABLE:
// JDK core code
private void afterYield() {
int s = state();
assert (s == PARKING || s == YIELDING) && (carrierThread == null);
if (s == PARKING) {
setState(PARKED);
// notify JVMTI that unmount has completed, thread is parked
if (notifyJvmtiEvents) notifyJvmtiUnmountEnd(false);
// may have been unparked while parking
if (parkPermit && compareAndSetState(PARKED, RUNNABLE)) {
// lazy submit to continue on the current thread as carrier if possible
lazySubmitRunContinuation();
}
} else if (s == YIELDING) { // Thread.yield
setState(RUNNABLE);
// notify JVMTI that unmount has completed, thread is runnable
if (notifyJvmtiEvents) notifyJvmtiUnmountEnd(false);
// lazy submit to continue on the current thread as carrier if possible
lazySubmitRunContinuation();
}
}
This closes the circle. As we can see, it takes a lot of work to follow the life cycle of a virtual thread and its continuation. A lot of native calls are involved. We hope that the JDK team will provide better documentation of the virtual threads implementation in the future.
Finally, we come to the end of this article. In the beginning, we introduced the reason behind the introduction of virtual threads in the JVM. Then, we saw how to create and use it with some examples. We made some examples of pinned threads, and finally, we saw how some old best practices are no longer valid when using virtual threads.
Project Loom is still actively under development, and there are a lot of other exciting features in it. As we said, structural concurrency and scoped values are some of them. Project Loom will be a game changer in the Java world. This article will help you better understand virtual threads and how to use them.
As promised, here is the pom.xml file that we used to run the code in this article:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>in.rcard</groupId>
<artifactId>virtual-threads-playground</artifactId>
<packaging>jar</packaging>
<version>1.0.0-SNAPSHOT</version>
<name>Java Virtual Threads Playground</name>
<properties>
<maven.compiler.source>19</maven.compiler.source>
<maven.compiler.target>19</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>edge-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.4.5</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (maybe moved to parent pom) -->
<plugins>
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.2.0</version>
</plugin>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.0</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
<configuration>
<release>19</release>
<compilerArgs>--enable-preview</compilerArgs>
</configuration>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.0.0-M7</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>3.0.1</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>3.0.0</version>
</plugin>
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>4.0.0-M3</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.4.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
<repositories>
<repository>
<id>projectlombok.org</id>
<url>https://projectlombok.org/edge-releases</url>
</repository>
</repositories>
</project>
Share on: