Riccardo Cardin
23 min read •

Share on:
Modern distributed applications need a communication system between their components that must be reliable, scalable, and efficient. Synchronous communication based on HTTP is not a choice in such applications due to latency problems, insufficient resources’ management, etc… Hence, we need an asynchronous messaging system capable of quickly scaling, robust to errors, and low latency.
Apache Kafka is a message broker that in the last years proved to have the above features. What’s the best way to interact with such a message broker, if not with the ZIO ecosystem? Hence, ZIO provides an asynchronous, reliable, and scalable programming model, which perfectly fits the feature of Kafka.
In this article, we will go through some primary Kafka’s use cases. First, we will read messages from Kafka and process them. Then, we will focus on writing some information to Kafka. In both cases, we will use the library zio-kafka. We will use a system handling football tournament scores as the use case to describe such features.
So, let’s proceed without further ado.
Following this article will require a basic understanding of how Kafka works. Moreover, we should know what the effect pattern is and how ZIO implements it (refer to ZIO Fibers: Concurrency and Lightweight Threads, and to Organizing Services with ZIO and ZLayers for further details).
Apache Kafka is the standard de-facto within messaging systems. Every Kafka installation has a broker, or a cluster of brokers, which allows its clients to write and read messages in a structure called topic, which are essentially distributed queues. The clients writing into topics are called producers, whereas consumers read information from topics.
Kafka treats each message as a sequence of bytes without imposing any structure or schema on the data. It’s up to clients to eventually interpret such bytes with a particular schema. Moreover, any message can have an associated key. The broker doesn’t decrypt the key in any way, as done for the message itself.
Moreover, the broker divides every topic into partitions, which are at the core of Kafka’s resiliency and scalability. In fact, every partition stores only a subset of messages, divided by the broker using the hash of the message’s key. Partitions are distributed among the cluster of brokers, and they are replicated to guarantee high availability.
Consumers read the messages from topics they subscribed to. A consumer reads messages within a partition in the same order in which they were produced. In detail, we can associate a consumer with a consumer group.
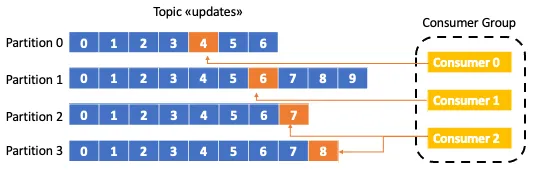
Consumers within the same consumer groups share the partitions of a topic. So, Adding more consumers to a consumer group means increasing the parallelism in consuming topics.
Now that you have a PhD in Kafka (the docs will also help), let’s proceed to our setup.
First, we need the dependencies from the zio-kafka and zio-json libraries:
libraryDependencies ++= Seq(
"dev.zio" %% "zio-kafka" % "0.15.0",
"dev.zio" %% "zio-json" % "0.1.5"
)
Then, during the article, all the code will use the following imports:
import org.apache.kafka.clients.producer._
import zio._
import zio.blocking.Blocking
import zio.clock.Clock
import zio.console.Console
import zio.duration.durationInt
import zio.json._
import zio.kafka.consumer._
import zio.kafka.producer.{Producer, ProducerSettings}
import zio.kafka.serde.Serde
import zio.stream._
import java.util.UUID
import scala.util.{Failure, Success}
Moreover, we need a Kafka broker up and running to allow our producers and consumer to write and read messages from topics. Simplifying the job, we are going to use version 2.7 of Kafka inside a Docker container (please, refer to Get Docker to get Docker up and running on your machine). There are many Kafka images on Docker Hub, but I prefer to use the image from Confluent:
version: "2"
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:6.2.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
We must copy the above configuration inside a docker-compose.yml file. As we see, Kafka also needs ZooKeeper to coordinate brokers inside the cluster. From version 2.8, Kafka doesn’t use ZooKeeper anymore. However, the feature is still experimental, so it’s better to avoid it for the moment.
Once set up the docker-compose file, let’s start the broker with the following command:
docker-compose up -d
The broker is now running inside the container called broker, and it’s listening to our messages on port 9092. To be sure that ZooKeeper and Kafka started, just type docker-compose ps to see the status of the active container. We should have an output similar to the following:
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
broker /etc/confluent/docker/run Up 0.0.0.0:29092->29092/tcp,:::29092->29092/tcp, 0.0.0.0:9092->9092/tcp,:::9092->9092/tcp, 0.0.0.0:9101->9101/tcp,:::9101->9101/tcp
zookeeper /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp,:::2181->2181/tcp, 2888/tcp, 3888/tcp
Moreover, during the article, we will need to run some commands inside the container. To access the Kafka container, we will use the following command:
docker exec -it broker bash
Now that everything is up and running, we can proceed with introducing the zio-kafka library.
First, we are going to analyze how to consume messages from a topic. As usual, we create a handy use case to work with.
Imagine we like football very much, and we want to be continuously updated with the results of the UEFA European Championship, EURO 2020. For its nerdy fans, the UEFA publishes the updates of the matches on a Kafka topic, called updates. So, once the Kafka broker is up and running, we create the topic using the utilities the Kafka container gives. As we just saw, we can connect to the container and create the topic using the following command:
kafka-topics \
--bootstrap-server localhost:9092 \
--topic updates \
--create
(Obviously, the Kafka broker of the UEFA is running on our machine at localhost).
Now that we created the topic, we can configure a consumer to read from it. Usually, we configure Kafka consumers using a map of settings. The zio-kafka library uses its own types to configure a consumer:
val consumerSettings: ConsumerSettings =
ConsumerSettings(List("localhost:9092"))
.withGroupId("stocks-consumer")
Here we have the minimum configuration needed: The list of Kafka brokers in the cluster and the group-id of the consumer. As we said, all the consumers sharing the same group-id belong to the same consumer group.
The ConsumerSettings is a builder-like class that exposes many methods to configure all the properties a consumer needs. For example, we can give the consumer any known property using the following procedure:
// zio-kafka library code
def withProperty(key: String, value: AnyRef): ConsumerSettings =
copy(properties = properties + (key -> value))
Or, we can configure the polling interval of the consumer just using the reliable method:
// zio-kafka library code
def withPollInterval(interval: Duration): ConsumerSettings =
copy(pollInterval = interval)
Here we can dive into all the available configuration properties for a Kafka consumer: Consumer Configurations.
Once we created the needed configuration, it’s time to complete the Kafka consumer. As each consumer owns an internal connection pool to connect to the broker, we don’t want to leak such a pool in case of failure.
In the ZIO ecosystem, a type like this is called ZManaged[R, E, A]. The ZManaged[R, E, A] is a data structure that encapsulates the acquisition and the release of a resource of type A using R, and that may fail with an error of type E.
So, let’s create the resource handling the connection to the Kafka broker:
val managedConsumer: RManaged[Clock with Blocking, Consumer.Service] =
Consumer.make(consumerSettings)
In this particular case, we obtain an instance of an RManaged, that in the ZIO jargon is a resource that cannot fail. Moreover, we see that the consumer depends upon the Blocking service. As the documentation says
In fact, ZIO internally uses such a service to manage the connection pool to the broker for a consumer.
Last but not least, we create a ZLayer from the managedConsumer, allowing us to provide it as a service to any component depending on it (for a comprehensive introduction to the ZLayer type, please refer to the article Organizing Services with ZIO and ZLayers):
val consumer: ZLayer[Clock with Blocking, Throwable, Consumer] =
ZLayer.fromManaged(managedConsumer)
Now that we obtained a managed, injectable consumer, we can consume some message from the broker. It’s time to introduce ZStream.
The zio-kafka library allows consuming messages read from a Kafka topic as a stream. Basically, a stream is an abstraction of a possible infinite collection. In ZIO, we model a stream using the type ZStream[R, E, A], which represents an effectful stream requiring an environment R to execute, eventually failing with an error of type E, and producing values of type A.
We used the effectful adjective because a ZStream implements the Effect Pattern: It’s a blueprint, or a description, of how to produce values of type A. In fact, the actual execution of the code is postponed. In other words, a ZIO always succeeds with a single value, whereas a ZStream succeeds with zero or more values, potentially infinitely many.
Another essential feature of the ZStream type is implicit chunking. By design, Kafka consumers poll (consume) from a topic a batch of messages (configurable using the max.poll.records). So, each invocation of the poll method on the Kafka consumer should return a collection (a Chunk in ZIO jargon) o messages.
The ZStream type flattened the list of Chunks for us, treating them as they were a single and continuous flux of data.
The creation of the stream consists of subscribing a consumer to a Kafka topic and configuring key and value bytes interpretation:
val matchesStreams: ZStream[Consumer, Throwable, CommittableRecord[String, String]] =
Consumer.subscribeAnd(Subscription.topics("updates"))
.plainStream(Serde.string, Serde.string)
The above code introduces many concepts. So, let’s analyze them one at a time.
First, a CommitableRecord[K, V] wraps the official Kafka class ConsumerRecord[K, V]. Basically, Kafka associates with every message a lot of metadata represented as a ConsumerRecord:
// zio-kafka library code
final case class CommittableRecord[K, V](record: ConsumerRecord[K, V], offset: Offset)
A critical piece of information is the offset of the message, which represents its position inside the topic partition. A consumer commits an offset within a consumer group after it successfully processed a message, marking that all the messages with a lower offset have been read.
As the subscription object takes a list of topics, a consumer can subscribe to many topics. In addition, we can use a pattern to tell the consumer which topics to subscribe to. Imagine we have a different topic for the updates of every single match. Hence, the names of the topics should reflect this information, for example, using a pattern like "updates|ITA-ENG". If we want to subscribe to all the topics associated with a match of the Italian football team, we can do the following:
val itaMatchesStreams: SubscribedConsumerFromEnvironment =
Consumer.subscribeAnd(Subscription.pattern("updates|.*ITA.*".r))
In some weird cases, we would be interested in subscribing a consumer not to a random partition of a topic but to a specific topic partition. As Kafka guarantees the ordering of the messages only locally to a partition, a scenario is when we need to preserve such order also in message elaboration. In this case, we can use the dedicated subscription method and subscribe to partition 1 of the topic updates:
val partitionedMatchesStreams: SubscribedConsumerFromEnvironment =
Consumer.subscribeAnd(Subscription.manual("updates", 1))
Once we subscribed to a topic, we must instruct our consumers how to interpret messages coming from it. Apache Kafka introduced the concept of serde, which stands for _ser_ializer and _de_serializer. We give the suitable Serde types both for messages’ keys and values during the materialization of the read messages into a stream:
Consumer.subscribeAnd(Subscription.topics("updates"))
.plainStream(Serde.string, Serde.string)
The plainStream method takes two Serde as parameters, the first for the key and the second for the value of a message. Fortunately, the zio-kafka library comes with Serde for common types:
// zio-kafka library code
private[zio] trait Serdes {
lazy val long: Serde[Any, Long]
lazy val int: Serde[Any, Int]
lazy val short: Serde[Any, Short]
lazy val float: Serde[Any, Float]
lazy val double: Serde[Any, Double]
lazy val string: Serde[Any, String]
lazy val byteArray: Serde[Any, Array[Byte]]
lazy val byteBuffer: Serde[Any, ByteBuffer]
lazy val uuid: Serde[Any, UUID]
}
In addition, we can use more advanced serialization/deserialization capabilities. For example, we can derive a Serde directly from another one using the inmap family of functions:
// zio-kafka library code
trait Serde[-R, T] extends Deserializer[R, T] with Serializer[R, T] {
def inmap[U](f: T => U)(g: U => T): Serde[R, U]
def inmapM[R1 <: R, U](f: T => RIO[R1, U])(g: U => RIO[R1, T]): Serde[R1, U]
}
Hence, we will use the inmap function if the derivation is not effectful, for example, if it always succeeds. Otherwise, we will use the inmapM if the derivation can produce side effects, such as throwing an exception. For example, imagine that each Kafka message has a JSON payload, representing a snapshot of a match during the time:
{
"players": [
{
"name": "ITA",
"score": 3
},
{
"name": "ENG",
"score": 2
}
]
}
We can represent the same information using Scala classes:
case class Player(name: String, score: Int)
case class Match(players: Array[Player])
So, we need to define a decoder, an object that can transform the JSON string representation of a match in an instance of the Match class. Luckily, the ZIO ecosystem has a project that can help us: The zio-json library.
We will not go deeper into the zio-json library since it’s not the article’s primary focus. However, let’s see together the easiest way to declare a decoder and an encoder. So, we start with the decoder. If the class we want to decode has already the fields’ names equal to the JSON fields, we can declare a JsonDecoder type class with just one line of code:
object Player {
implicit val decoder: JsonDecoder[Player] = DeriveJsonDecoder.gen[Player]
}
object Match {
implicit val decoder: JsonDecoder[Match] = DeriveJsonDecoder.gen[Match]
}
The type class adds to the String type the following extension method, which lets us decode a JSON string into a class:
// zio-json library code
def fromJson[A](implicit A: JsonDecoder[A]): Either[String, A]
As we can see, the above function returns an Either object mapping a failure as a String.
In the same way, we can declare a JsonEncoder type class:
object Player {
implicit val encoder: JsonEncoder[Player] = DeriveJsonEncoder.gen[Player]
}
object Match {
implicit val encoder: JsonEncoder[Match] = DeriveJsonEncoder.gen[Match]
}
This time, the type class adds a method to our type that encodes it into a JSON string:
// zio-json library code
def toJson(implicit A: JsonEncoder[A]): String
Now, we just assemble all the pieces we just created using the inmapM function:
val matchSerde: Serde[Any, Match] = Serde.string.inmapM { matchAsString =>
ZIO.fromEither(matchAsString.fromJson[Match].left.map(new RuntimeException(_)))
} { matchAsObj =>
ZIO.effect(matchAsObj.toJson)
}
We have only mapped the Either object’s left value resulting from the decoding into an exception. In this way, we honor the signature of the ZIO.fromEither factory method.
Finally, it’s usual to encode Kafka messages’ values using some form of binary compressions, such as Avro. In this case, we can create a dedicated Serde directly from the raw type org.apache.kafka.common.serialization.Serde coming from the official Kafka client library. In fact, there are many implementations of Avro serializers and deserializer, such as Confluent KafkaAvroSerializer and KafkaAvroDeserializer.
We can read typed messages from a Kafka topic. As we said, the library shares the messages with developers using a ZStream. In our example, the produced stream has the type ZStream[Consumer, Throwable, CommittableRecord[UUID, Match]]:
val matchesStreams: ZStream[Consumer, Throwable, CommittableRecord[UUID, Match]] =
Consumer.subscribeAnd(Subscription.topics("updates"))
.plainStream(Serde.uuid, matchSerde)
Now, what should we do with them? If we read a message, maybe we want to process it somehow, and ZIO lets us use all the functions available in the ZStream type. We might be requested to map each message. ZIO gives us many variants of the map function. The main two are the following:
def map[O2](f: O => O2): ZStream[R, E, O2]
def mapM[R1 <: R, E1 >: E, O2](f: O => ZIO[R1, E1, O2]): ZStream[R1, E1, O2]
As we can see, the difference is if the transformation is effectful or not. Let’s map the payload of the message in a String, suitable for printing:
matchesStreams
.map(cr => (cr.value.score, cr.offset))
The map function uses utility methods we defined on the Match and Player types:
case class Player(name: String, score: Int) {
override def toString: String = s"$name: $score"
}
case class Match(players: Array[Player]) {
def score: String = s"${players(0)} - ${players(1)}"
}
Moreover, it’s always a good idea to forward the offset of the message since we’ll use it to commit the message’s position inside the partition.
Using the information just transformed, we can now produce some side effects, such as writing the payload to a database or simply to the console. ZIO defines the tap method for doing this:
// zio-kafka library code
def tap[R1 <: R, E1 >: E](f0: O => ZIO[R1, E1, Any]): ZStream[R1, E1, O]
So, after getting a printable string from our Kafka message, we print it to the console:
matchesStreams
.map(cr => (cr.value.score, cr.offset))
.tap { case (score, _) => console.putStrLn(s"| $score |") }
Once we finished playing with messages, it’s time for our consumer to commit the offset of the last read message. In this way, the next poll cycle will read a new set of information from the assigned partition.
The consumers from zio-kafka read messages from topics grouped in Chunk. As we said, the ZStream implementation allows us to forget about chunks during processing. However, to commit the right offset, we need to access the Chunk again.
Fortunately, the zio-stream libraries define a set of transformations that executes on Chunk and not on single elements of the stream: They’re called transducers, and the reference type is ZTransducer. The library defines a transducer as:
// zio-kafka library code
ZTransducer[-R, +E, -I, +O](
val push: ZManaged[R, Nothing, Option[Chunk[I]] => ZIO[R, E, Chunk[O]]]
)
Basically, it’s a wrapper around a function that obtains an effect of chunks containing values of type I from a resource that might produce a chunk containing type O values. The size of each chunk may vary during the transformation.
In our case, we are going to apply the Consumer.offsetBatches transducer:
// zio-kafka library code
val offsetBatches: ZTransducer[Any, Nothing, Offset, OffsetBatch] =
ZTransducer.foldLeft[Offset, OffsetBatch](OffsetBatch.empty)(_ merge _)
Broadly, the transducer merges the input offsets, where the merge function implements the classic max function in this case.
So, after the application of the offsetBatches transducer, each chunk of messages is mapped into a chunk containing only one element, which is their maximum offset:
matchesStreams
.map(cr => (cr.value.score, cr.offset))
.tap { case (score, _) => console.putStrLn(s"| $score |") }
.map { case (_, offset) => offset }
.aggregateAsync(Consumer.offsetBatches)
In reality, the OffsetBatch type is more than just an offset. In fact, the library defines the class as follows:
// zio-kafka library code
sealed trait OffsetBatch {
def offsets: Map[TopicPartition, Long]
def commit: Task[Unit]
def merge(offset: Offset): OffsetBatch
def merge(offsets: OffsetBatch): OffsetBatch
}
In addition to the information we’ve just described, the OffsetBtach type also contains the function that creates the effect to commits the offset to the broker, i.e. def commit: Task[Unit].
Great. Now we know for every chunk which is the offset to commit. How can we do that? There are many ways of doing this, among which we can use a ZSink function. As in many other streaming libraries, sinks represent the consuming function of a stream. After the execution of a sink, the values of the stream are not available to further processing.
The ZSink type has many built-in operations, and we are going to use one of the easier, the foreach function, which applies an effectful function to all the values emitted by the sink.
So, commit the offsets prepared by the previous transducer is equal to declare a ZSink invoking the commit function on each OffsetBatch it emits:
matchesStreams
.map(cr => (cr.value.score, cr.offset))
.tap { case (score, _) => console.putStrLn(s"| $score |") }
.map { case (_, offset) => offset }
.aggregateAsync(Consumer.offsetBatches)
.run(ZSink.foreach(_.commit))
The result of the application of the above whole pipeline of operation is a ZIO[Console with Any with Consumer with Clock, Throwable, Unit], which means an effect that writes to the console something that it read from a Kafka consumer and can fail with a Throwable, and finally produces no value. When somebody asks why we also need a Clock to execute the effect, the answer is that the transducer runs operations on chunks directly using Fibers, so it requires the ability to schedule them properly.
When we use ZStream, we must remember that the default behavior for a stream when encountering a failure is to fail the stream. Until now, we developed the happy path, which is when everything goes fine. However, many errors can arise during messages elaboration.
One of the possibles is the deserialization error of the messages. We define as a poison pill a message having a schema that can’t be deserialized. If it’s not managed correctly, reading a poison pill message will terminate the whole stream.
Fortunately, zio-kafka let us deserialize the key and the value of a massage in a Try, just calling the asTry method of a Serde:
Consumer.subscribeAnd(Subscription.topics("updates"))
.plainStream(Serde.uuid, matchSerde.asTry)
In this way, if something goes wrong during the deserialization process, the developer can teach the program how to react without abruptly terminating the stream:
Consumer.subscribeAnd(Subscription.topics("updates"))
.plainStream(Serde.uuid, matchSerde.asTry)
.map(cr => (cr.value, cr.offset))
.tap { case (tryMatch, _) =>
tryMatch match {
case Success(matchz) => console.putStrLn(s"| ${matchz.score} |")
case Failure(ex) => console.putStrLn(s"Poison pill ${ex.getMessage}")
}
}
Usually, a poison pill message is correctly logged as an error, and its offset is committed as a regular message.
Now that we have a consumer that can read messages from the updates topic, we are ready to execute our program and produce some messages. Summing up, the overall program is the following:
object EuroGames extends zio.App {
case class Player(name: String, score: Int) {
override def toString: String = s"$name: $score"
}
object Player {
implicit val decoder: JsonDecoder[Player] = DeriveJsonDecoder.gen[Player]
implicit val encoder: JsonEncoder[Player] = DeriveJsonEncoder.gen[Player]
}
case class Match(players: Array[Player]) {
def score: String = s"${players(0)} - ${players(1)}"
}
object Match {
implicit val decoder: JsonDecoder[Match] = DeriveJsonDecoder.gen[Match]
implicit val encoder: JsonEncoder[Match] = DeriveJsonEncoder.gen[Match]
}
val matchSerde: Serde[Any, Match] = Serde.string.inmapM { matchAsString =>
ZIO.fromEither(matchAsString.fromJson[Match].left.map(new RuntimeException(_)))
} { matchAsObj =>
ZIO.effect(matchAsObj.toJson)
}
val consumerSettings: ConsumerSettings =
ConsumerSettings(List("localhost:9092"))
.withGroupId("updates-consumer")
val managedConsumer: RManaged[Clock with Blocking, Consumer.Service] =
Consumer.make(consumerSettings)
val consumer: ZLayer[Clock with Blocking, Throwable, Has[Consumer.Service]] =
ZLayer.fromManaged(managedConsumer)
val matchesStreams: ZIO[Console with Any with Consumer with Clock, Throwable, Unit] =
Consumer.subscribeAnd(Subscription.topics("updates"))
.plainStream(Serde.uuid, matchSerde)
.map(cr => (cr.value.score, cr.offset))
.tap { case (score, _) => console.putStrLn(s"| $score |") }
.map { case (_, offset) => offset }
.aggregateAsync(Consumer.offsetBatches)
.run(ZSink.foreach(_.commit))
override def run(args: List[String]): URIO[zio.ZEnv, ExitCode] =
matchesStreams.provideSomeLayer(consumer ++ zio.console.Console.live).exitCode
}
Since we’ve not talked about producers in zio-kafka yet, we need to produce some messages using the kafka-console-producer utility. First of all, we have to connect to the broker container. Then, we start an interactive producer using the following shell command:
kafka-console-producer \
--topic updates \
--broker-list localhost:9092 \
--property parse.key=true \
--property key.separator=,
As we can see, we are creating a producer that will send messages to the broker listening on port 9092 at localhost, and we will use the ',' character to separate the key from the payload of each message. Once entered the command, the shell waits for us to type the first message. Let’s proceed typing the following messages:
b91a7348-f9f0-4100-989a-cbdd2a198096,{"players":[{"name":"ITA","score":0},{"name":"ENG","score":1}]}
b26c1b21-41d9-4697-97c1-2a8d4313ae53,{"players":[{"name":"ITA","score":1},{"name":"ENG","score":1}]}
2a90a703-0be8-471b-a64c-3ea25861094c,{"players":[{"name":"ITA","score":3},{"name":"ENG","score":2}]}]}
If everything goes well, our zio-kafka consumer should start printing to the console the read information:
| ITA: 0 - ENG: 1 |
| ITA: 1 - ENG: 1 |
| ITA: 3 - ENG: 2 |
As it should be obvious, the zio-kafka library also provides Kafka producers in addition to consumers. As we made for consumers, if we want to produce some messages to a topic, the first thing to do is to create the resource and the layer associated with a producer:
val producerSettings: ProducerSettings = ProducerSettings(List("localhost:9092"))
val producer: ZLayer[Blocking, Throwable, Producer[Any, UUID, Match]] =
ZLayer.fromManaged(Producer.make[Any, UUID, Match](producerSettings, Serde.uuid, matchSerde))
The ProducerSettings follows the same principles of the ConsumerSettings type we’ve already analyzed. The only difference is that the properties we can provide are those related to producers. Refer to Producer Configurations for further details.
Once we created a set of settings listing at least the URI of the broker we are going to send the messages to, we build a Producer resource, and we surround inside a ZLayer. We must provide explicit information of types in the Producer.make smart constructor: The first parameter refers to the environment used by ZIO to create the two Serde, whereas the second and the third parameters refer to the type of the keys and of the values of messages respectively.
To send messages to a topic, we have many choices. In fact, the Producer module exposes many accessor functions to send messages. Among the others, we find the following:
// zio-kafka library code
object Producer {
def produce[R, K, V](record: ProducerRecord[K, V]): RIO[R with Producer[R, K, V], RecordMetadata]
def produce[R, K, V](topic: String, key: K, value: V): RIO[R with Producer[R, K, V], RecordMetadata]
def produceChunk[R, K, V](records: Chunk[ProducerRecord[K, V]]): RIO[R with Producer[R, K, V], Chunk[RecordMetadata]]
}
As we can see, we can produce a single message or a chunk. Also, we can specify the topic, key, and value of the message directly, or we can work with the ProducerRecord type, which already contains them. In our scenario, for the sake of simplicity, we decide to produce a single message:
val itaEngFinalMatchScore: Match = Match(Array(Player("ITA", 3), Player("ENG", 2)))
val messagesToSend: ProducerRecord[UUID, Match] =
new ProducerRecord(
"updates",
UUID.fromString("b91a7348-f9f0-4100-989a-cbdd2a198096"),
itaEngFinalMatchScore
)
val producerEffect: RIO[Producer[Any, UUID, Match], RecordMetadata] =
Producer.produce[Any, UUID, Match](messagesToSend)
Also, if we want the Scala compiler to understand the types of our variable correctly, we have to help it, and specify the types requested by the Producer.produce function. The type semantic is the same as with the Producer.make smart constructor.
Hence, the produced effect requests a Producer[Any, UUID, Match] as environment type. To execute the effect, we just provide the producer layer we defined above:
producerEffect.provideSomeLayer(producer).exitCode
We can compose the production of the messages and the consumption directly in one program using fibers (see ZIO Fibers: Concurrency and Lightweight Threads for further details on ZIO fibers):
val program = for {
_ <- matchesStreams.provideSomeLayer(consumer ++ zio.console.Console.live).fork
_ <- producerEffect.provideSomeLayer(producer) *> ZIO.sleep(5.seconds)
} yield ()
program.exitCode
In this article, we started learning the library zio-kafka introducing the basics of Kafka and how to set up a working environment using Docker. Then, we focused on the consumer part, and we learned how to subscribe to a topic. We talked about serialization and deserialization of messages, going into details of zio-json. The consumption of messages through the ZIO stream was the next issue. Finally, the article talked about producers and gave an example merging all the previous topics together. I hope you enjoyed the journey.
Share on: